如何解决MySQL主从复制太慢的问题

导致备库延迟的原因主要有如下几种:
通常备库所在机器的性能要比主库所在的机器性能差,执行备份自然会更慢。
备库的读压力大。在备库过多的执行繁重的查询任务。
大事务。因为主库上必须等事务执行完成才会写入 binlog,再传给备库。一次性地用 delete 语句删除太多数据、表 DDL都可能造成延迟。
主库是多线程操作,而从库却只有一个线程在执行复制。
提升从库物理机的配置,性能差异不要太大。
业务的持久化层的实现采用分库架构,mysql服务可平行扩展,分散压力。
采用读写分离,分散主库压力。
加入缓存如Redis等,降低mysql的读压力。
避免执行大事务等费时的操作,可以将事务内容拆开执行。
使用同步并行复制方案MTS
COMMIT_ORDER,表示的就是前面介绍的,根据同时进入 prepare 和 commit 来判断是否可以并行的策略。
WRITESET,表示的是对于事务涉及更新的每一行,计算出这一行的 hash 值,组成集合 writeset。如果两个事务没有操作相同的行,也就是说它们的 writeset 没有交集,就可以并行。
WRITESET_SESSION,是在 WRITESET 的基础上多了一个约束,即在主库上同一个线程先后执行的两个事务,在备库执行的时候,要保证相同的先后顺序。
解决方案:
从MySQL5.6开始支持并行复制,这就解决了之前复制速度缓慢的问题。coordinator 就是原来的 sql_thread, 他负责读取中转日志和分发事务。真正更新日志的,变成了 worker 线程。work 线程的个数由参数 slave_parallel_workers 决定的。既然是并行就一定会有数据一致性的问题,两个不同的事务如果在不同的work中同时执行,顺序的影响也会造成结果不同。
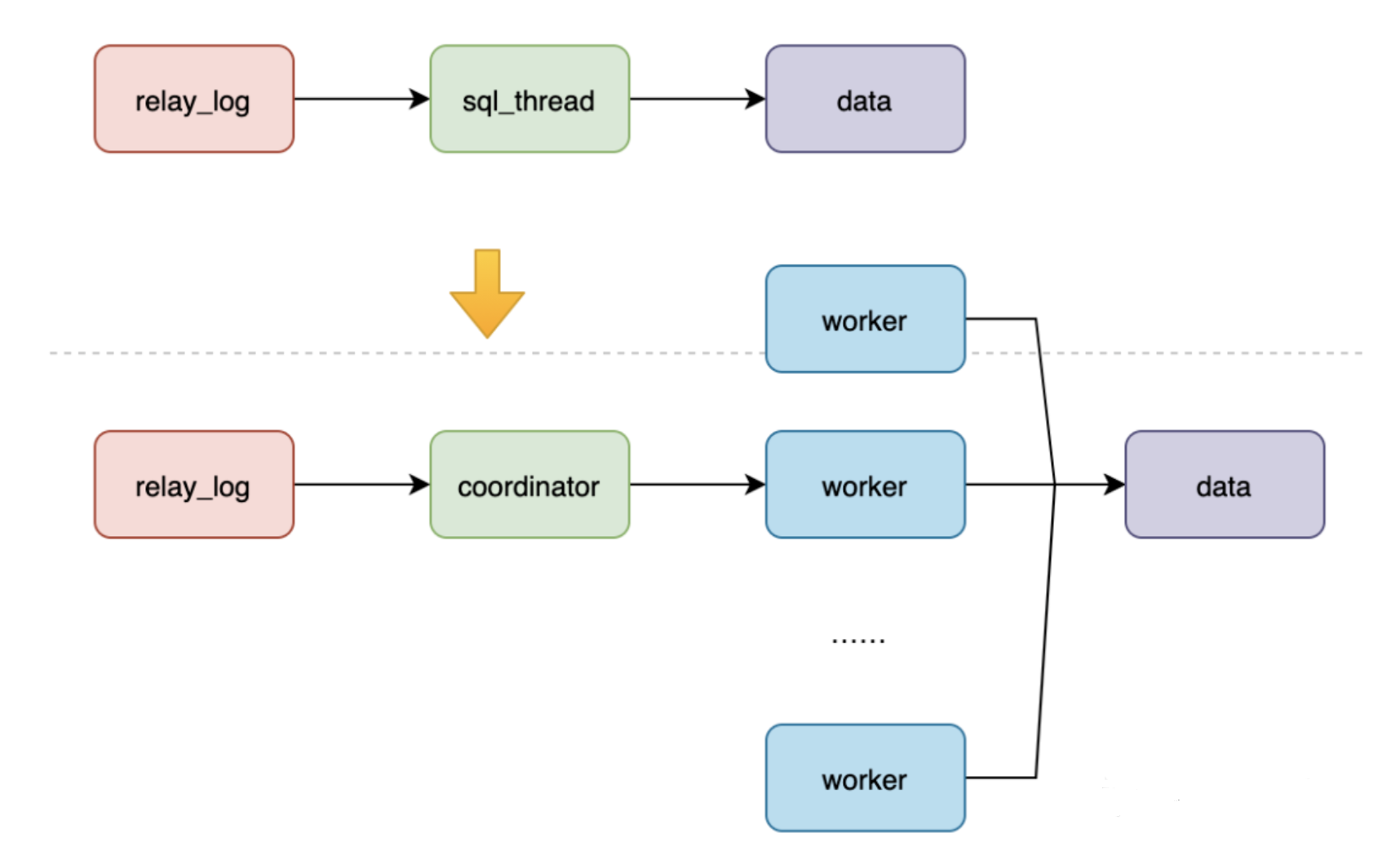
所以在 coordinator 分发任务的时候,要满足以下这两个基本要求:
不能造成更新覆盖。这就要求更新同一行的两个事务,必须被分发到同一个 worker 中。
同一个事务不能被拆开,必须放到同一个 worker 中。
各个版本的多线程复制,都遵循了这两条基本原则。
官方 MySQL5.6 版本,支持了并行复制,只是支持的粒度是按库并行。用于决定分发策略的 hash 表里,key 就是数据库名,同一个数据库需要在同一个worker中串行执行,这就避免了事务之间相互影响的问题。
MariaDB 的并行复制策略利用redo log 组提交 (group commit) 优化的特性:能够在同一组里提交的事务,一定不会修改同一行。所以可以按照食物的 commit—_id来分组。
在实现上,MariaDB 是这么做的:
在一组里面一起提交的事务,有一个相同的 commit_id,下一组就是 commit_id+1;
commit_id 直接写到 binlog 里面;传到备库应用的时候,相同 commit_id 的事务分发到多个 worker 执行;
这一组全部执行完成后,coordinator 再去取下一批。
MySQL5.7中对 MariaDB 多策略进行了优化。因为同时处于 prepare 状态的事务,在备库执行时是可以并行的,此时的redolog已经经过了并行验证,所以从库也可以执行。具体步骤不做赘述,参考MariaDB策略。
在 2018 年 4 月份发布的 MySQL 5.7.22 版本里(最新5.7.37),MySQL 增加了一个新的并行复制策略,基于 WRITESET 的并行复制。相应地,新增了一个参数 binlog-transaction-dependency-tracking,用来控制是否启用这个新策略。这个参数的可选值有以下三种。
当然为了唯一标识,这个 hash 值是通过“库名 + 表名 + 索引名 + 值”计算出来的。如果一个表上除了有主键索引外,还有其他唯一索引,那么对于每个唯一索引,insert 语句对应的 writeset 就要多增加一个 hash 值。
总结一下,MySQL 并行复制策略主要是有三种思想:
按照库的级别粒度并行执行,用于决定分发策略的 hash 表里,key 就是数据库名。
按照行级别,根据id、唯一索引、value、库名这些来计算hash值,做分组标示
根据redo log 持久化原理,同一个commit组 或者 同时进入prepare或者commit表示可以同步执行。